Local Multi-Node Spark Cluster in a DevContainer – Zero Setup, Plug and Play
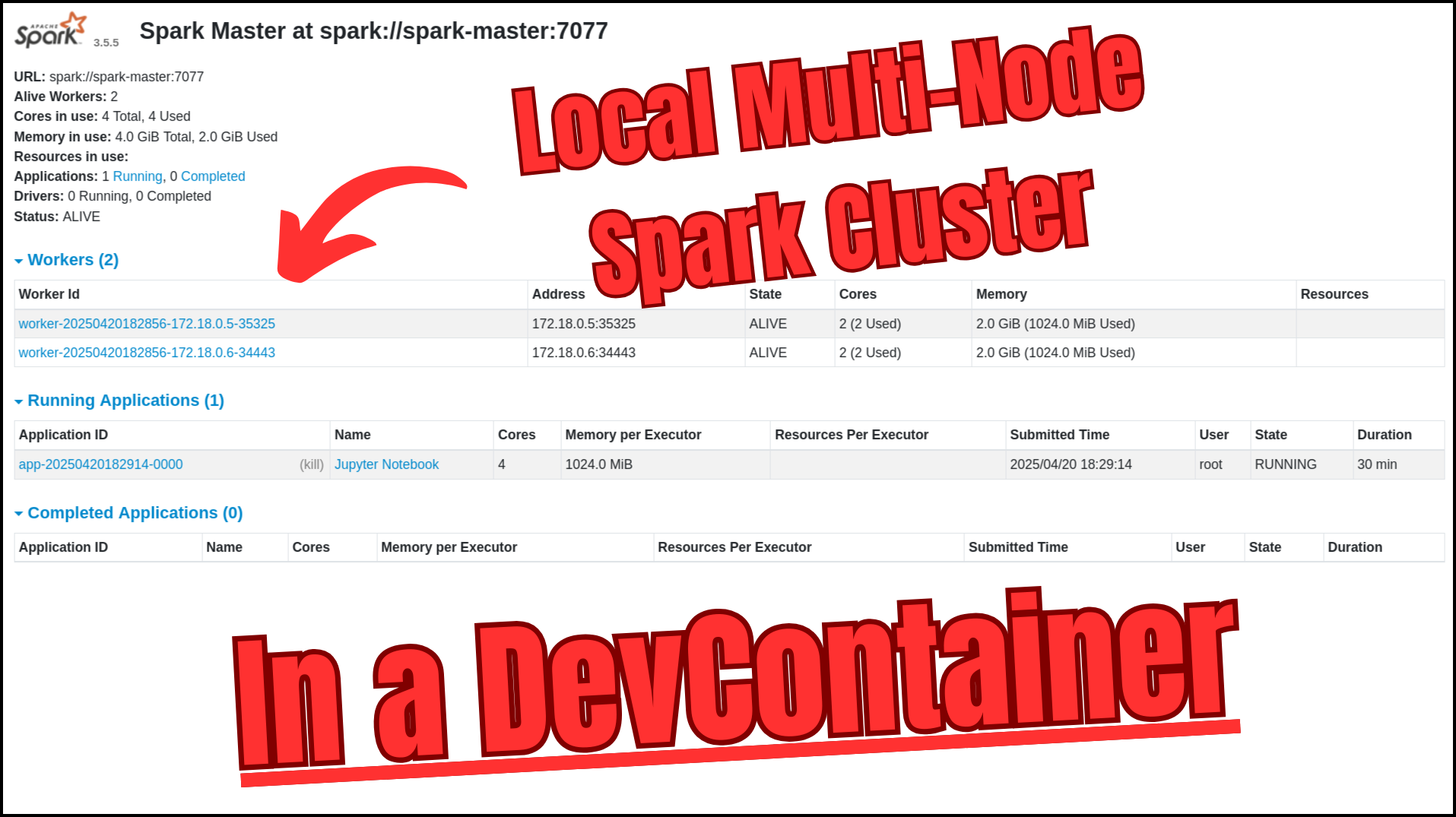
Data engineering workflows with Apache Spark often involve complex setup procedures, environment configuration, and dependency management. Traditional approaches to creating local Spark development environments frequently lead to “works on my machine” problems, inconsistent behavior across team members’ setups, and significant time spent on configuration rather than actual development.
This article presents a solution that creates a complete, production-like Spark cluster locally using a DevContainer with Docker Compose. The setup includes a Spark master, multiple worker nodes, history server, Jupyter server — all in a development environment with PySpark and Jupyter notebooks integration — configured automatically and ready to use.
The complete setup with the full code and a condensed explanation is available and linked at the bottom of this article.
Why a Local Spark DevContainer?
- Multi-node testing — Simulate distributed workloads on a real cluster.
- Zero setup — Launch everything with a single command.
- Consistency — Every developer shares the exact same config.
- Isolation — Avoid conflicts with local software installs.
- Version control — Track environment changes in your repository.
New to DevContainers?
I’ve written a three-part guide on DevContainers, covering the basics to advanced workflows: Check out the full series below:
- DevContainers Introduction: The Ideal Standardized Team Development Environment — Part 1/3
- DevContainers Improved: Integrating Code Quality Checks for Continuous Feedback — Part 2/3
- DevContainers Mastered: Automating Manual Workflows with VSCode Tasks — Part 3/3
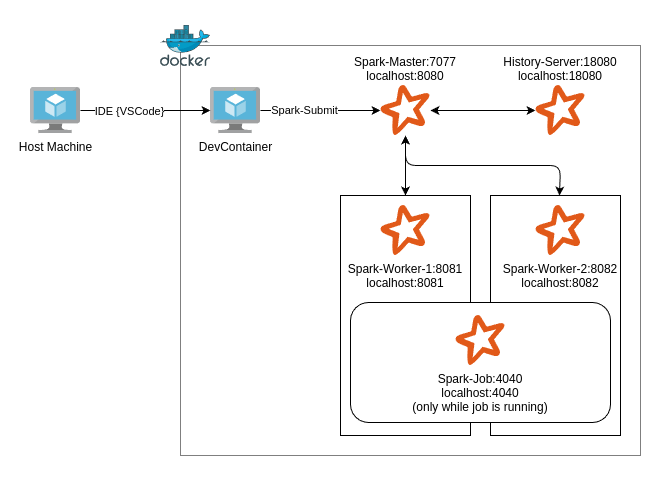
DevContainer Cluster Architecture
The local cluster is composed of:
- DevContainer: Python, Spark, Jupyter, and CLI tools.
- Spark Master: Schedules jobs and manages cluster state.
- Two Spark Workers: Simulate distributed compute.
- Spark History Server: View and debug completed jobs.
All services run on a private Docker network. The Spark master is reachable at spark://spark-master:7077 from within the containers. Key UIs are exposed to the host.
Solving Spark’s Networking Challenges
Running Spark in containers introduces unique networking challenges due to its distributed nature. This setup solves them through:
-
Named hostnames — All containers are assigned hostnames and a
SPARK_LOCAL_IP(e.g., spark-master, devcontainer), ensuring consistent internal DNS resolution. - Driver-to-worker routing — spark.driver.host=devcontainer allows workers to contact the Spark driver inside the DevContainer.
- Interface binding — spark.driver.bindAddress=0.0.0.0 ensures the driver listens on all interfaces, an
-
Accessing Web UI — setting
SPARK_PUBLIC_DNSupdates the URLs on the WEB UI to use localhost as address instead of internal Docker IPs.
Accessing the UIs
Monitor the cluster via these local endpoints:
| UI Component | URL | Description |
|---|---|---|
| Spark Master | localhost:8080 | Cluster and application overview |
| Spark Worker 1 | localhost:8081 | Metrics and logs |
| Spark Worker 2 | localhost:8082 | Metrics and logs |
| History Server | localhost:18080 | View completed jobs |
| Application UI | localhost:4040 | Live application job monitoring |
Getting Started
- Download the Spark DevContainer folder from GitHub .
- Place it inside your project’s
.devcontainer/folder. - Open the repo in VSCode with the Dev Containers extension installed.
- Press
F1→ Dev Containers: Rebuild and Reopen in Container
That’s it. A full multi-node Spark cluster is now running locally alongside the DevContainer.
Submitting PySpark Jobs
You can run full PySpark jobs inside the DevContainer using either:
Just hit Ctrl+Shift+B This will trigger a predefined task that runs the following command:
1
2
3
4
5
6
/opt/spark/bin/spark-submit \
--master spark://spark-master:7077 \
--deploy-mode client \
--conf spark.driver.host=devcontainer \
--conf spark.driver.bindAddress=0.0.0.0 \
your_script.py
Native Jupyter Notebooks Support in VSCode
This setup supports native .ipynb execution inside VSCode — no browser, no token, no hassle.
Just open a notebook file. The interpreter auto-connects to PySpark and launches by preloading the following SparkSession in the background. This can be found in the spark-init.py file which is added to Jupyter environment.
1
2
3
4
5
6
7
8
9
10
11
12
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("VSCode Notebook") \
.master("spark://spark-master:7077") \
.config("spark.driver.host", "devcontainer") \
.config("spark.driver.bindAddress", "0.0.0.0") \
.config("spark.ui.port", "4040") \
.getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("WARN")
Behind the Scenes: Configuration Highlights
The power of this solution lies in its detailed configuration. Let’s explore each component and understand why specific choices were made.
DevContainer Configuration: The Developer Experience
The DevContainer is the primary environment where developers work. Its configuration focuses on creating a seamless experience with all the necessary tools pre-configured.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
{
"customizations": {
"vscode": {
"extensions": [
"ms-toolsai.jupyter",
"ms-toolsai.datawrangler",
],
"settings": {
// Jupyter notebook integration
"jupyter.interactiveWindow.textEditor.executeSelection": true,
"jupyter.notebookFileRoot": "${workspaceFolder}",
"jupyter.kernelSpecConnectionMetadata": [
{
"kernelspec": {
"name": "pyspark",
"display_name": "PySpark"
}
}
],
// Task for submitting Spark jobs
"tasks": {
"version": "2.0.0",
"tasks": [
{
"label": "spark-submit current file",
"type": "shell",
"command": "${workspaceFolder}/.devcontainer/spark/spark-submit.sh ${file}",
"group": {
"kind": "build",
"isDefault": true
},
"presentation": {
"reveal": "always",
"panel": "new"
}
}
]
}
}
}
}
}
DevContainer Dockerfile
The DevContainer is created via a Dockerfile in the Docker-Compose. It installs Java, Spark, Pyspark, Jupyter, and more by default. Meaning, everything is included in the image and does not require to be installed by the user anymore. The added benefit is that all team members are running the exact same environment.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
ARG PYTHON_VERSION=3.10
FROM python:${PYTHON_VERSION}-bullseye
# Install Java and other dependencies
RUN apt-get update && \
apt-get install -y --no-install-recommends \
openjdk-11-jdk \
wget \
procps \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
# Set environment variables
ENV JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
# Arguments for Spark setup
ARG SPARK_VERSION=3.5.5
ARG HADOOP_VERSION=3
# Set Spark environment variables
ENV SPARK_VERSION=${SPARK_VERSION}
ENV HADOOP_VERSION=${HADOOP_VERSION}
ENV SPARK_HOME=/opt/spark
ENV PATH=$PATH:$SPARK_HOME/bin
# Download and install Spark
RUN wget -q https://archive.apache.org/dist/spark/spark-${SPARK_VERSION}/spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
tar -xzf spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz && \
mv spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION} /opt/spark && \
rm spark-${SPARK_VERSION}-bin-hadoop${HADOOP_VERSION}.tgz
# Install Python dependencies including Jupyter
RUN pip install --no-cache-dir \
pyspark==${SPARK_VERSION} \
jupyter \
jupyterlab \
ipykernel
# Set up a Jupyter kernel with auto Spark initialization
RUN python -m ipykernel install --name pyspark --display-name "PySpark" && \
mkdir -p /root/.ipython/profile_default/startup/
# Create startup script for auto Spark initialization
COPY spark_init.py /root/.ipython/profile_default/startup/00-spark-init.py
# Create a Jupyter kernel for PySpark
RUN ipython kernel install --user --name=pyspark --display-name='PySpark'
WORKDIR /workspace
CMD ["sleep", "infinity"]
Docker Compose Configuration: Orchestrating the Cluster
The Docker Compose file is the heart of this solution. It orchestrates multiple containers to create a complete Spark cluster environment.
This configuration includes several advanced Docker Compose features:
-
YAML Anchors and Templates: The
x-spark-worker-templatedefines a reusable template for worker nodes, reducing duplication and ensuring consistency. This follows the DRY (Don’t Repeat Yourself) principle. -
Environment Variable Substitution: Variables like
${SPARK_VERSION}are populated from the.envfile, making the configuration highly customizable without editing the compose file. -
Volume Management: The setup uses named volumes for logs and events, ensuring data persistence between container restarts. It also mounts the project directory to
/workspacein all containers. -
Network Isolation: A dedicated
spark-networkconnects all containers, providing isolation and consistent name resolution. -
Port Mapping: All necessary UI and communication ports are explicitly mapped to make them accessible from the host machine. It is a careful balance of connectivity between the docker containers while changing the URLs via
SPARK_PUBLIC_DNSto set the correct URLs in the Spark web UI.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
version: '3.4'
# Worker template that will be reused
x-spark-worker-template: &spark-worker-template
image: apache/spark:${SPARK_VERSION}
command: "/opt/spark/bin/spark-class org.apache.spark.deploy.worker.Worker spark://spark-master:${SPARK_MASTER_PORT}"
environment:
- SPARK_PUBLIC_DNS=localhost # For UI URLs to be accessible from host
- SPARK_LOCAL_IP=spark-worker-1 # Will be overridden by specific workers
volumes:
- spark-logs:/opt/spark/logs
- spark-events:/opt/spark/events
- ./spark-defaults.conf:/opt/spark/conf/spark-defaults.conf
- ../../:/workspace
networks:
- spark-network
depends_on:
- spark-master
restart: unless-stopped
services:
# Development environment with all tools installed
devcontainer:
build:
context: .
dockerfile: ./Dockerfile
args:
- SPARK_VERSION=${SPARK_VERSION}
- HADOOP_VERSION=3
- PYTHON_VERSION=${PYTHON_VERSION}
volumes:
- ../../:/workspace
networks:
- spark-network
ports:
- "4040:4040" # Expose Spark application UI
environment:
- SPARK_LOCAL_IP=0.0.0.0
- SPARK_DRIVER_HOST=devcontainer
- SPARK_PUBLIC_DNS=localhost
- SPARK_MASTER_URL=spark://spark-master:${SPARK_MASTER_PORT}
# Spark master node
spark-master:
image: apache/spark:${SPARK_VERSION}
command: "/opt/spark/bin/spark-class org.apache.spark.deploy.master.Master"
hostname: spark-master
environment:
- SPARK_MASTER_HOST=spark-master
- SPARK_MASTER_PORT=${SPARK_MASTER_PORT}
- SPARK_MASTER_WEBUI_PORT=${SPARK_MASTER_WEBUI_PORT}
- SPARK_PUBLIC_DNS=localhost # For UI URLs to be accessible from host
- SPARK_LOCAL_IP=spark-master # Keep internal hostname for Docker network communication
ports:
- "${SPARK_MASTER_WEBUI_PORT}:${SPARK_MASTER_WEBUI_PORT}" # Web UI
- "${SPARK_MASTER_PORT}:${SPARK_MASTER_PORT}" # Spark master port
volumes:
- spark-logs:/opt/spark/logs
- spark-events:/opt/spark/events
- ./spark-defaults.conf:/opt/spark/conf/spark-defaults.conf
- ../../:/workspace
networks:
- spark-network
depends_on:
- devcontainer
restart: unless-stopped
# Worker nodes using the template
spark-worker-1:
<<: *spark-worker-template
hostname: spark-worker-1
environment:
- SPARK_WORKER_CORES=${SPARK_WORKER1_CORES}
- SPARK_WORKER_MEMORY=${SPARK_WORKER1_MEMORY}
- SPARK_WORKER_WEBUI_PORT=${SPARK_WORKER1_WEBUI_PORT}
- SPARK_PUBLIC_DNS=localhost # For UI URLs to be accessible from host
- SPARK_LOCAL_IP=spark-worker-1 # Keep internal hostname for Docker network communication
ports:
- "${SPARK_WORKER1_WEBUI_PORT}:${SPARK_WORKER1_WEBUI_PORT}" # Worker 1 UI
spark-worker-2:
<<: *spark-worker-template
hostname: spark-worker-2
environment:
- SPARK_WORKER_CORES=${SPARK_WORKER2_CORES}
- SPARK_WORKER_MEMORY=${SPARK_WORKER2_MEMORY}
- SPARK_WORKER_WEBUI_PORT=${SPARK_WORKER2_WEBUI_PORT}
- SPARK_PUBLIC_DNS=localhost # For UI URLs to be accessible from host
- SPARK_LOCAL_IP=spark-worker-2 # Keep internal hostname for Docker network communication
ports:
- "${SPARK_WORKER2_WEBUI_PORT}:${SPARK_WORKER2_WEBUI_PORT}" # Worker 2 UI
# History server has no dependencies - keeps running independently
spark-history-server:
image: apache/spark:${SPARK_VERSION}
command: "/opt/spark/bin/spark-class org.apache.spark.deploy.history.HistoryServer"
hostname: spark-history
environment:
- SPARK_PUBLIC_DNS=localhost
- SPARK_LOCAL_IP=0.0.0.0
ports:
- "${SPARK_HISTORY_WEBUI_PORT}:${SPARK_HISTORY_WEBUI_PORT}" # History UI
volumes:
- spark-logs:/opt/spark/logs
- spark-events:/opt/spark/events
- ./spark-defaults.conf:/opt/spark/conf/spark-defaults.conf
networks:
- spark-network
restart: unless-stopped
networks:
spark-network:
driver: bridge
volumes:
spark-logs:
spark-events:
Environment Configuration: Centralized Control
The .env file provides a single location to customize the entire environment. It is automatically loaded by docker-compose.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
# Spark configuration
SPARK_VERSION=3.5.5
PYTHON_VERSION=3.11
# Spark Master
SPARK_MASTER_WEBUI_PORT=8080
SPARK_MASTER_PORT=7077
# Spark Worker 1
SPARK_WORKER1_CORES=2
SPARK_WORKER1_MEMORY=2G
SPARK_WORKER1_WEBUI_PORT=8081
# Spark Worker 2
SPARK_WORKER2_CORES=2
SPARK_WORKER2_MEMORY=2G
SPARK_WORKER2_WEBUI_PORT=8082
# Spark History Server
SPARK_HISTORY_WEBUI_PORT=18080
Extending the DevContainer
The base DevContainer can be extended for specific use cases:
- Additional Libraries: Add Python packages to the Dockerfile
- Custom Configurations: Mount additional configuration files into the containers
- Integration with Other Services: Add services like PostgreSQL or Kafka to the Docker Compose file
For example, to add PostgreSQL for storing processed data:
1
2
3
4
5
6
7
8
9
10
11
12
13
# Add to docker-compose.yml
postgres:
image: postgres:14
environment:
- POSTGRES_PASSWORD=postgres
- POSTGRES_USER=postgres
- POSTGRES_DB=sparkdata
ports:
- "5432:5432"
volumes:
- postgres-data:/var/lib/postgresql/data
networks:
- spark-network
Conclusion
The Spark cluster DevContainer provides a comprehensive, production-like environment for local development with minimal setup. By containerizing the entire Spark stack, it eliminates configuration headaches and ensures consistency across team members.
This approach aligns with modern DevOps practices by treating development environments as code, making them reproducible, shareable, and version-controlled. The result is a more efficient development cycle and more reliable testing for Spark applications.
All code for this DevContainer setup is available on GitHub and can be adapted to specific project requirements.
🔗 GitHub – .devcontainer Spark Multi-Node Cluster Development Environment